![]()
GitHub fora do ar: falha global afeta push e pull de repositórios
Resumo rápido: A Cloudflare confirmou ter enfrentado, no dia 18 de novembro de 2025, o pior apagão global de sua história recente. A falha derrubou por mais de cinco horas serviços essenciais como ChatGPT, X/Twitter, Workers KV e milhares de sites ao redor do mundo. Após a estabilização, o CEO Matthew Prince assumiu a responsabilidade e detalhou medidas para evitar novos incidentes.
Conteúdos deste artigo
- Apagão da Cloudflare: o que aconteceu
- O que disse o CEO Matthew Prince
- Recuperação e retorno da normalidade
- Medidas preventivas e novas políticas
- Impacto e lições para o ecossistema da internet
- Principais dúvidas sobre o apagão da Cloudflare
- Considerações finais
Apagão da Cloudflare: o que aconteceu
A instabilidade teve início às 8h28 da manhã e rapidamente se espalhou pela rede global da Cloudflare. Cerca de 20% dos sites protegidos pela empresa começaram a exibir erros HTTP 5xx. Plataformas populares, aplicativos de IA, sites de streaming e até sistemas internos da própria Cloudflare ficaram indisponíveis.
Após análise, a Cloudflare identificou que o problema foi desencadeado por uma atualização incorreta no sistema anti-bot. Uma alteração interna gerou um arquivo de configuração com colunas duplicadas. Quando esse arquivo foi processado pelo ClickHouse — banco de dados responsável por análises de tráfego — ocorreu um consumo anormal de recursos, causando sobrecarga nos servidores centrais e resultando em falhas em cascata.

GitHub fora do ar? Queda do GitHub confirmada
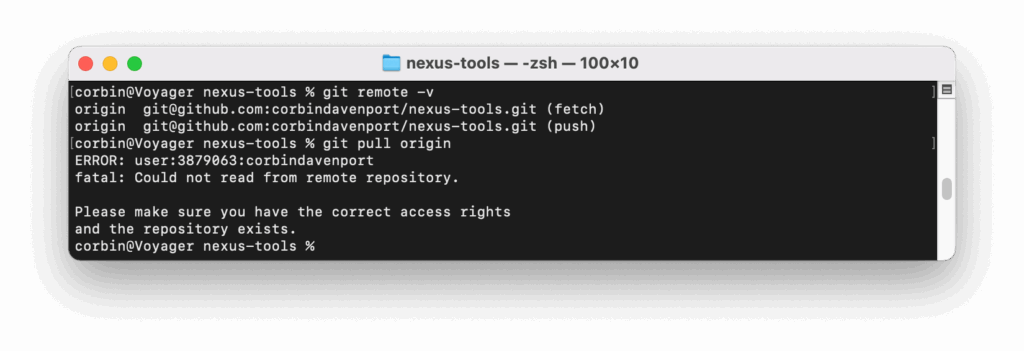
Relatos em tempo real no Downdetector e nas redes sociais aumentam desde o final da manhã, indicando falhas em funcionalidades essenciais. O portal oficial de status da plataforma, GitHub Status, confirmou o incidente, descrevendo uma “disponibilidade degradada” nas operações Git. Os serviços do Copilot, API, webhooks, pull requests e GitHub Actions continuam funcionando normalmente.
Segundo os dados, a falha afeta diretamente comandos Git — como git pull e git push —, impedindo o sincronismo de repositórios remotos. Mensagens de erro como “Could not read from remote repository” têm se tornado frequentes entre usuários que tentam atualizar ou enviar alterações para seus projetos.
O que disse o CEO Matthew Prince
“Qualquer interrupção em qualquer um de nossos sistemas é inaceitável. Sabemos que falhamos hoje e que a responsabilidade é totalmente nossa.”
— Matthew Prince, CEO da Cloudflare
Prince explicou que o arquivo corrompido “dobrou de tamanho” devido à duplicação de colunas e, ao ser carregado, tornou o módulo anti-bot incapaz de operar. Isso provocou interrupções em serviços externos e também em produtos internos da empresa, como Cloudflare Access e Workers KV.
Recuperação e retorno da normalidade
A normalização completa aconteceu por volta das 14h06. A equipe técnica precisou agir rapidamente para:
- remover e substituir arquivos internos corrompidos;
- reiniciar servidores críticos;
- reduzir cargas e limpar dados duplicados;
- reconfigurar rotas e proxies afetados.
Serviços de monitoramento como o Downdetector registraram milhares de notificações simultâneas em diversos países, evidenciando a dimensão global do incidente.
Medidas preventivas e novas políticas
Após estabilizar o sistema, a Cloudflare anunciou quatro ações imediatas para evitar que falhas semelhantes se repitam:
- 1. Validação rigorosa de arquivos internos: Configurações internas agora passam por verificações automáticas de integridade, tamanho e estrutura antes de serem aplicadas.
- 2. Botões de emergência globais: Criação de mecanismos que permitem desligar módulos problemáticos em toda a rede com um único comando.
- 3. Controle inteligente de logs e dumps: Em caso de incidentes, relatórios técnicos serão limitados para evitar congestionamento de servidores.
- 4. Simulações periódicas de falhas críticas: A empresa passará a realizar testes recorrentes com redundância avançada em proxies e roteadores internos.
A empresa destacou que os “botões de emergência” serão implementados primeiro, já que o apagão mostrou a importância de controles de desligamento rápido.
Impacto e lições para o ecossistema da internet
O apagão revelou um ponto sensível da infraestrutura digital moderna: a dependência global de poucos provedores como Cloudflare, Google Cloud, AWS e Akamai. Quando um deles falha, mesmo parcialmente, os efeitos são sentidos por empresas, governos e usuários comuns.
Especialistas em infraestrutura destacam que plataformas críticas devem considerar:
- multi-CDN para distribuição de tráfego;
- redundância geográfica real em múltiplas regiões;
- monitoramento independente de uptime (fora da Cloudflare);
- testes periódicos de resiliência sob cenários de falha.
A própria Cloudflare anunciou que reforçará seus sistemas de redundância e investirá em simulações de falhas controladas.
Principais dúvidas sobre o apagão da Cloudflare
Qual foi a causa principal do apagão?
Uma atualização interna mal configurada, que gerou um arquivo com colunas duplicadas no sistema anti-bot. Ao ser processado pelo ClickHouse, isso sobrecarregou servidores críticos.
Quais serviços foram afetados?
ChatGPT, X/Twitter, Workers KV, Cloudflare Access, dashboards internos e milhares de sites hospedados na rede da Cloudflare.
A falha foi causada por um ataque hacker?
Não. A Cloudflare confirmou que o problema foi interno e não teve relação com ataques ou invasões.
Quanto tempo durou o apagão?
Cerca de 5h30, entre 8h28 e 14h06.
O que a Cloudflare fará para evitar novos incidentes?
Validação rigorosa de arquivos internos, botões de emergência globais, limitação automática de logs e simulações recorrentes de falhas críticas.
Considerações finais
O apagão global de novembro de 2025 marca um divisor de águas para a infraestrutura da internet. Embora negativo, o episódio reforça a necessidade de transparência, redundância e práticas robustas de governança técnica. A postura da Cloudflare em assumir a responsabilidade e detalhar suas ações corretivas estabelece um padrão importante para outras empresas do setor.
Para quem depende da internet para trabalhar, vender, criar conteúdo ou operar sistemas críticos, o incidente serve como alerta para investir em redundância, monitoramento independente e estratégias de continuidade.
Fonte: The Verge, RendaGeek






